NVDLA架构分析
1. NVDLA总体架构分析
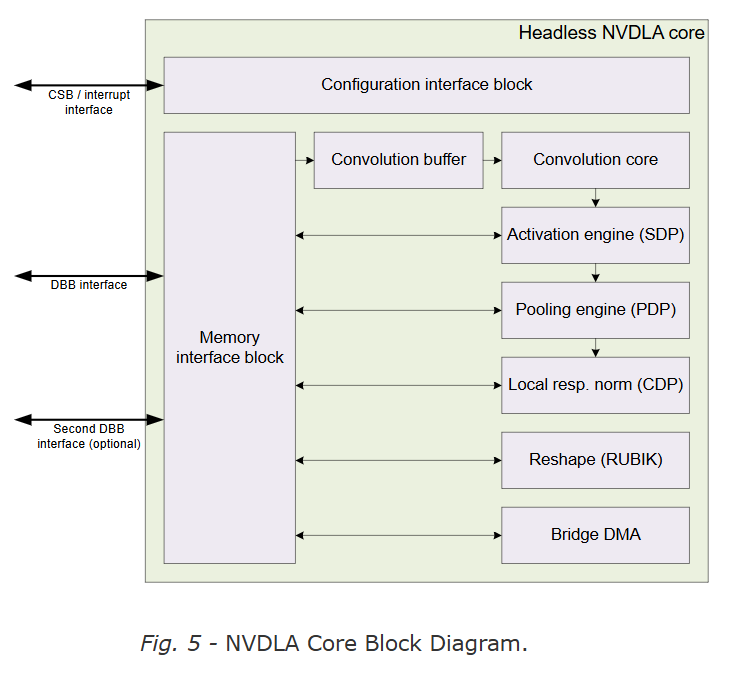
NVDLA(NVIDIA Deep Learning Accelerator)是一种可配置的硬件神经网络加速器,他通过独立的模块加速各个CNN网络的各个层,且这些模块相互独立可以分开从而有着更好的灵活性。其基础架构图如上所示,接下来是对于其中模块进行介绍。
首先是对于四种接口的介绍
- CSB(Configuration Space Bus,CSB),这是一种简单的低性能总线主要用于主系统对于NVDLA做一些像配置寄存器这样简单的任务。
- IQR(External interrupt) 这个接口主要向主系统进行NVDLA状态的汇报,通过其可以知道NVDLA内部的状态,如发生异常、操作完成等
- DBB(Data BackBone) NVDLA有着自己的DMA系统来访问系统内部内存,从而达到直接搬移数据的操作,其主要是AMBA AXI-4这种高性能总线。
- SRAMIF(SRAM Connection) 有一些系统有着对于高吞吐量,低延迟的要求或者希望使用小的SRAM作为Cache,这时像DRAM这种高延迟的存储器显然已经不符合要求,所以有着第二条DBB用于访问SRAM,以提高NVDLA的性能满足系统的要求
然后是对于各个子模块的简单介绍,为了支持加速CNN推理中的各个层并将其解耦,NVDLA主要将其分为5个group,每个group对应于CNN推理中的一个操作。
- 卷积操作(Convolution core和 Convolution buffer)
- 单数据定点操作(Activation engine block)
- 平面数据操作(Pooling engine block)
- 多平面操作(Local resp. norm)
- 数据存储和Reshape操作(Reshape and Bridge DMA blocks)
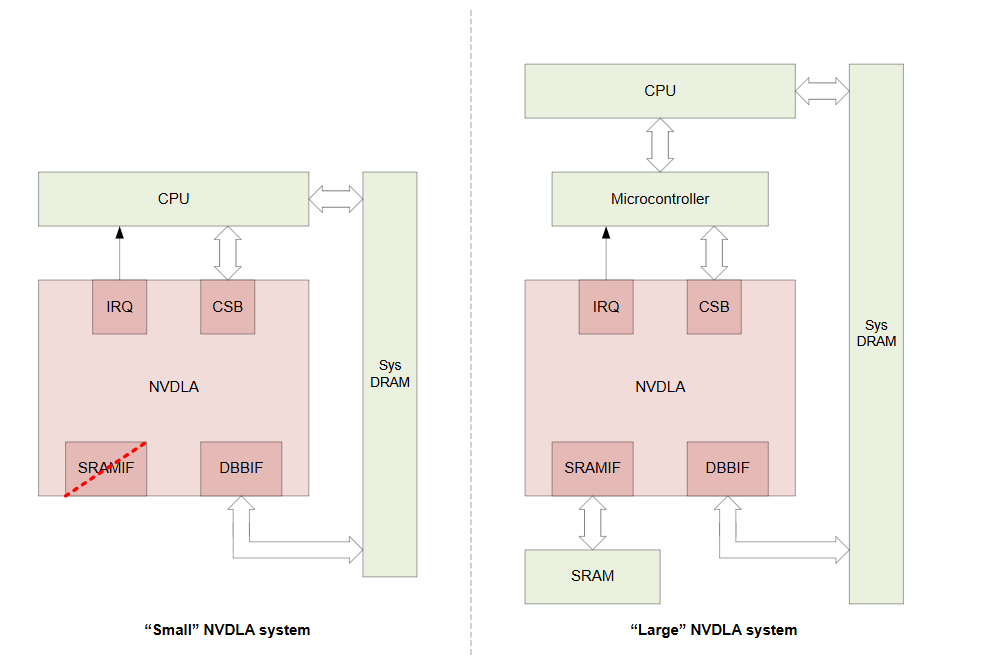
NVDLA手册给出了两种系统结构设计的参考使用样例分别对应了不同应用场景,具体的如下图所示,首先对于一些边缘设备,功耗是首要考虑的因素,所以此时 “Small NVDLA System” 更加合适,CPU直接通过总线控制NVDLA,NVDLA通过DBB接口直接从内存搬运数据。对于一些性能要求高的场景,”Large NVDLA System”更加合适,此时加入了一个控制协处理器帮助CPU调控NVDLA,并提供了一个高带宽的SRAM支持NVDLA子系统。
2. NVDLA各个模块分析
2.1 Bridge DMA
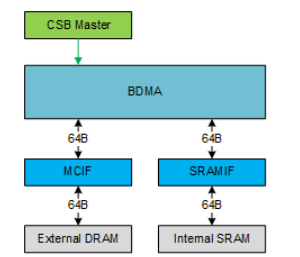
在上文提到对于一些高性能的场景,需要同时用到外部的DRAM和外部的SRAM,而BDMA就提供了一个媒介使得DRAM和SRAM可以进行数据的交互。具体架构如下图所示,Bridge DMA有着两路DMA接口分别接入SRAM和DRAM,其贷款为64bytes,支持突发长度为4。
值得注意的是,为了移动一个cube的所有数据,BDMA支持行重复模式,能够在各行之间进行地址跳转,以获取多行数据,从而映射一个表面。此外,BDMA 还支持更高一层的重复——即对多行数据抓取的重复,从而映射多个表面,最终映射整个立方体。
- 行重复
- BDMA 可以按固定地址间隔(stride)连续读取多行数据(例如 N 行)。
- 每行内部是连续的内存块(如 H×W 数据),而行间通过地址跳转(如 stride)分离。
- 主要适用于处理二维数据(图像的一层表面、矩阵)
- 多层重复
- 在“行重复”基础上,再嵌套一层循环,实现三维数据(立方体)的批量搬运。
- 适合处理三维数据结构(如视频帧、多通道特征图、张量计算)。
2.2 Convolution Pipeline
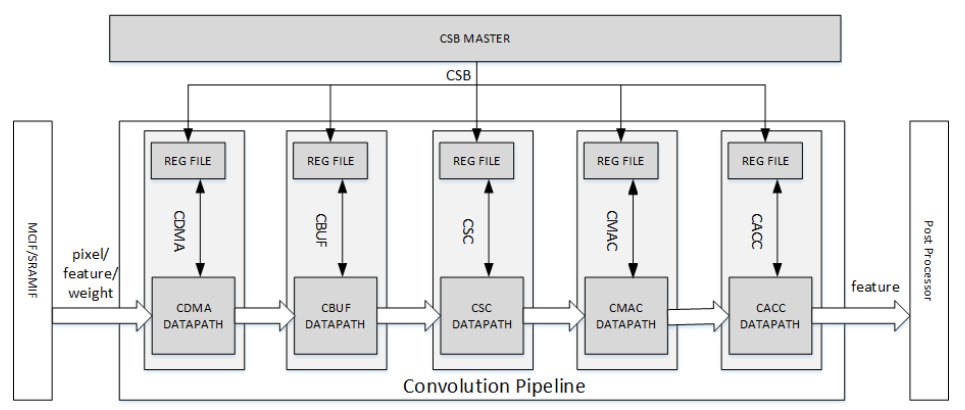
卷积流水线是NVDLA的核心组织,其主要作用就是对于卷积操作进行加速,它支持可编程参数以适配不同规模的卷积运算,并通过 Winograd 算法 和 多批次(multi-batch)处理 等特性提升性能,从而提高乘加运算(MAC)的效率。
卷积流水线是一个五级流水,分别有Convolution DMA(CDAMA)、Convolution Buffer(CBUF)、Convolution Sequnence Controller(CSC)、Convolution MAC(CMAC)、Convolution Accumulator(CACC)五个阶段,这每一个阶段都有着自己的单独寄存器可以通过CSB接口进行配置。
卷积流水线支持三种运算模式,分别是:
- 直接卷积(Direct Convolution, DC 模式) —— 用于特征数据的标准卷积计算
- 图像输入卷积(Image Input Mode) —— 针对图像输入的优化卷积处理
- Winograd 卷积(Winograd Mode) —— 基于 Winograd 算法的快速卷积实现
以下是对于每一个模块的具体介绍。
2.2.1 Convolution DMA
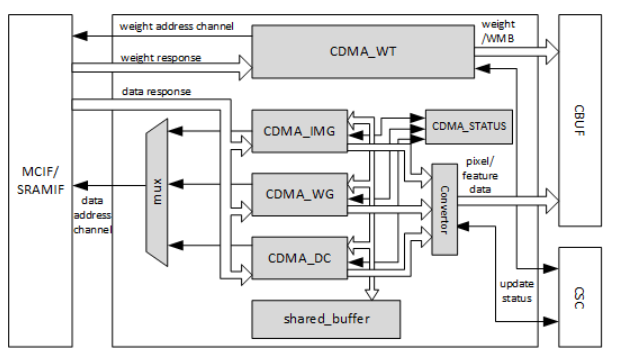
Convolution DMA主要负责从DRAM和SRAM获取数据供卷积运算使用,并以卷积引擎(Convolution Engine)所需的顺序存储到CBUF,目前支持的数据格式如下:
- 像素数据(Pixel Data)
- 特征数据(Feature Data)
- 未压缩/压缩的权重(Uncompressed/Compressed Weight)
- 权重掩码位(Weight Mask Bit,WMB) - 稀疏卷积
- 权重缩放因子(Weight Group Scalar, WGS) - 分组量化
具体的架构图如下所示,有两个读通道从CMDA连接到AXI接口处,分别是Weight Channel和Data Channel。CDMA只发送内存读取请求,所有的内存读请求的地址是64位对齐的。
CDMA 有三个子模块(CDMA_DC、CDMA_WG、CDMA_IMG)来负责获取数据供卷积使用,这些子模块的工作流程类似,唯一一点不同的有区别的是对于输入数据的重排序是不同的,在任何时刻只有一个子模块进行工作。
将CDMA_DC作为一个典型来介绍其工作流程
- 检查CBUF以确认有足够的空间
- 产生读事件
- 缓存特征图数据在共享buffer中
- 对于特征图数据进行重排序
- 产生卷积缓存写地址
- 对于卷积缓存进行数据写入
- 更新CDMA_STATUS中的状态
CDMA负责维护并传递权重缓冲区和输入数据缓冲区在CBUF的状态信息。在CDMA和CSC中,各保存有一份状态副本。两个模块通过交换 更新/释放信息,协同决定何时获取新的特征数据、像素数据、权重数据,以及何时释放这些数据单元。
2.2.2 Convolution Sequence Controller
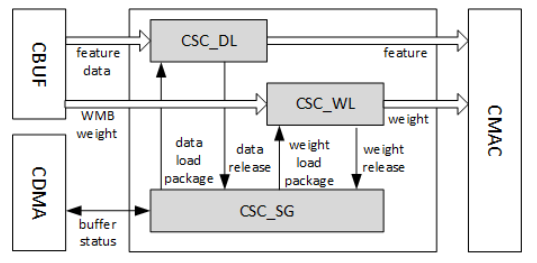
CSC主要负责从CBUF中取出权重数据、特征数据以及像素数据并将之送到CMAC进行运算,这是一个控制计算和传输的关键单元。
CSC主要分为三个子模块,分别是CSC_SG(Convolution Sequnece Generator)、CSC_WL(Weight Loader)、CSC_DL(Data Loader)。
CSC_SG主要负责产生sequence来控制卷积操作,具体的工作流程如下
- 轮询检查CBUF中是否有足够的数据和权重
- 生成sequence package包含weight sequence package和data sequence package,每一个sequence package代表一个stripe操作
- 将两种类型的package分别存入两个FIFO中
- 同时维护两个递减计数器,分别用于追踪权重加载进度,特征/像素加载进度。
- 当计数器归零时,检查CACC的Back pressure
- 如果所有条件准备好,将weight package和data package送入FIFO中
CSC_DL是负责执行特征/像素数据加载序列的模块。其功能包括:
- 接收来自CSC_SG的数据包;
- 从CBUF加载特征/像素数据,并传输至卷积乘法累加单元CMAC;
- 维护数据缓冲区的状态,并与CDMA通信以同步状态信息;
- 支持Winograd模式:对输入特征数据执行PRA(Pre-addition,预加法变换),完成数据格式转换。
CSC_WL是执行权重加载序列的模块,其功能包括:
- 接收来自CSC_SG的权重包;
- 从CBUF加载权重数据;
- 执行必要的权重解压缩(Decompression);
- 将处理后的权重发送至CMAC;
- 维护权重缓冲区的状态,并与CDMA_WT通信以同步状态信息。
3.需要补充的知识
3.1 Direct Convolution
3.2 Wingrad算法
Winograd 算法通过数学变换,用加法替代部分乘法,显著减少计算量,尤其适合小卷积核(如 3×3、5×5)。
其对应的步骤,以3*3卷积核和4*4输入块为例:
- 传统方法:需2*2*3*3 = 36次乘法
- Winograd方法:仅需4*4=16次乘法
计算公式:
\[Y = A^\mathsf{T} \left[ (G g G^\mathsf{T}) \odot (B^\mathsf{T} d B) \right] A\]其中:G、B和A是变换矩阵(用于输入、卷积核和输出的数学变换)
Wingrad算法的优缺点分析:
- 优势
- 减少乘法次数从而可以降低能耗
- 劣势
- 多次变换带来精度损失
- 需要存储变换矩阵,带来存储占用