Low-Power and Scalable Retention-Enhanced IGZO TFT eDRAM-Based Charge-Domain Computing
4T1C eDRAM Design for ACIM
4T1C eDRAM Design

将权重通过开关差分对形式保存,通过电阻分压的形式,读出权重值。
\[V_{RL}=\frac{1}{N}\sum_{i=1}^NV_{OUT,i}\]电容间电荷共享
阵列级仿真
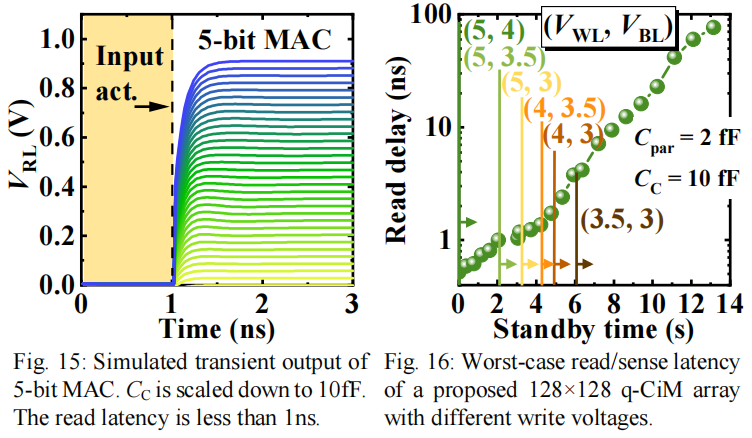
Fig.15展示了不同输入下的\(V_{RL}\)电压,Fig.16展示了不同\((V_{WL},V_{BL})\)最坏读延迟。
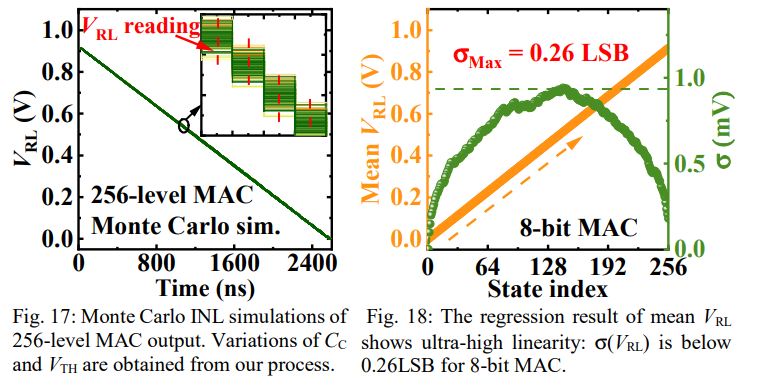
Fig.17展现了\(C_c与V_{th}\)蒙特卡罗非线性(INL)仿真,用于测量ADC测量值与真实值的差距,Fig.18则展示了随着VRL的增加其最大误差为0.26LSB
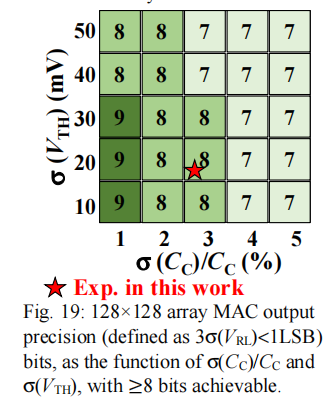
Fig.19通过改变\(V_{TH}和C_{c}\)从而控制128*128阵列输出的精度
架构级仿真
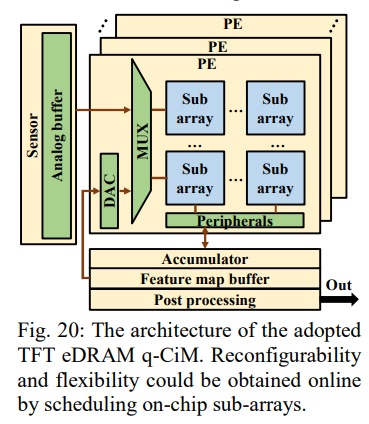
FIg.20为整体架构
baseline: 有i-CIM(IGZO),q-CIM(本文结构,CMOS),i-CIM(CMOS)
testbench: CIFAR-10数据集的图像分类在VGG-8算法上实现
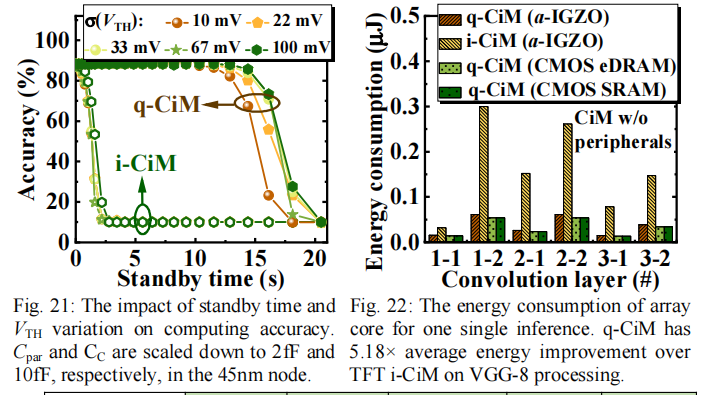
Fig.21展示了整体的精度,Fig.22展示了对于单个卷积层的功耗,因为i-CIM对于电荷损失比较敏感,所以随着standby time的增加i-CIM精度快速下降,而q-CIM对于电荷损失并不敏感.
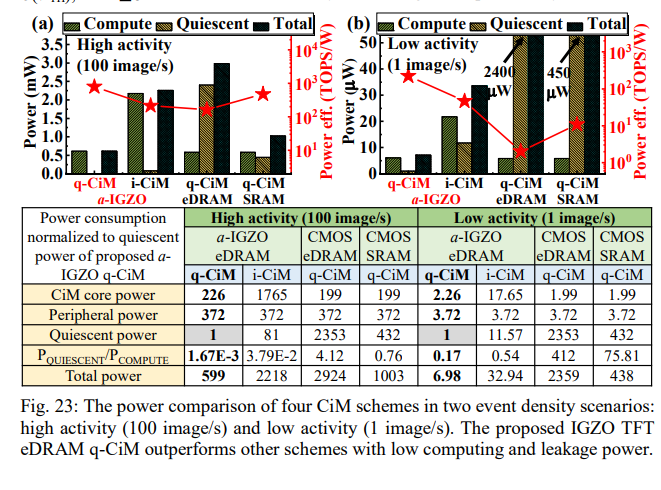
Fig.23展示了应用层上的功耗(包含CIM core、Peripheral power(A\D conversion,refresh costs))以及静止功耗,并比较了静止功耗与动态功耗之比
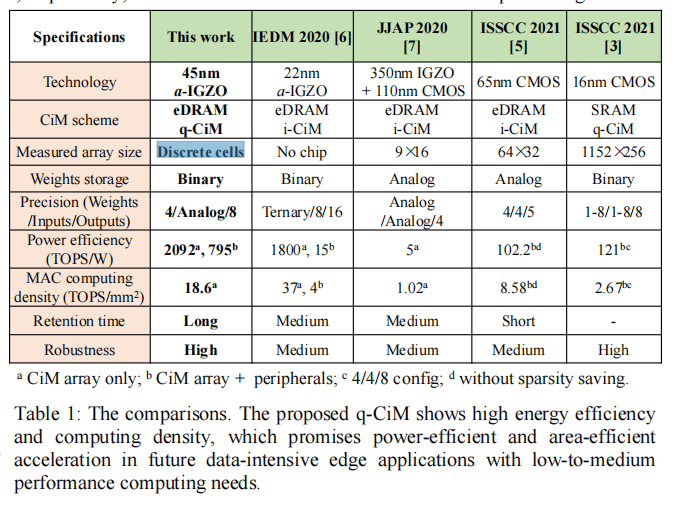
将本文结构与其他结构作对比,CIM core 有着2092 TOPS/s 以及加上外围设备有着795 TOPS/s的能效,并有着更好的保持时间和待机时间
This post is licensed under CC BY 4.0 by the author.